Wie funktioniert die Google-Suchmaschine?
Immer wieder fragen sich Nutzer, wie eigentlich das Prinzip der Indexierung in der Google-Suchmaschine funktioniert und nach welchen Maßstäben URLs in den Suchergebnissen gelistet und wieder entfernt werden.
Wir wollen ein wenig Licht ins Dunkel bringen und uns die Funktionsweise einer Index-Suchmaschine genauer anschauen. Ein Verständnis für die technischen Grundlagen zu entwickeln, zahlt sich oftmals aus. Denn so kann viel zielgerichteter beurteilt werden, welche SEO-Maßnahmen für die eigene Webseite wahrscheinlich den gewünschten Erfolg bringen.
Dabei ist das Thema durchaus komplex, denn der Suchalgorithmus funktioniert in Wahrheit nur über ein Zusammenspiel vieler verschiedener Instanzen. Um nicht den Rahmen zu sprengen, betrachten wir im Folgenden den vereinfachten Aufbau einer Suchmaschine.
Wir orientieren uns dabei chronologisch an dem Prozess, der dazu notwendig ist, dem Nutzer letztlich eine Liste mit relevanten Suchergebnissen im Browser-Fenster anzeigen zu können. Vor allem drei Hauptbestandteile sind für das Verständnis wichtig: Die Webcrawler, das Information Retrieval System (Indexer) und der Query Prozessor (Searcher).
Web-Crawling
Bevor ein Nutzer überhaupt eine Antwort auf eine Suchanfrage erhalten kann, müssen in den mächtigen Datenbanken, die hinter einer Suchmaschine stehen, URLs gelistet sein, die anschließend als Suchergebnis in Frage kommen. Da das Internet ständig im Wandel ist, permanent neue URLs hinzukommen und sich die Inhalte unter bestehenden URLs schnell verändern, muss im World Wide Web ein andauernder Screening-Prozess stattfinden.
Diese Aufgabe erledigen die Web Crawler der Suchmaschinen. Sie sind dafür zuständig, aktualisierte Inhalte und neue Webseiten zu finden, um diese in einem Repository Index (Datenbank) komprimiert abzulegen. Natürlich benötigen die Web Crawler dazu eine Grundlage, also bestehende URLs, die in einer weiteren Datenbank, dem Document Index, bereits hinterlegt sind. Diese werden nach einem bestimmten Zeitplan vom URL Server (auch „Scheduler“) an den Crawler übermittelt. Dieser ruft dann die URL auf und parst die Inhalte. Der Server des Repositories speichert diese dann wiederum komprimiert im Repository Index ab, wo diese im nächsten Schritt weiterverarbeitet werden können.
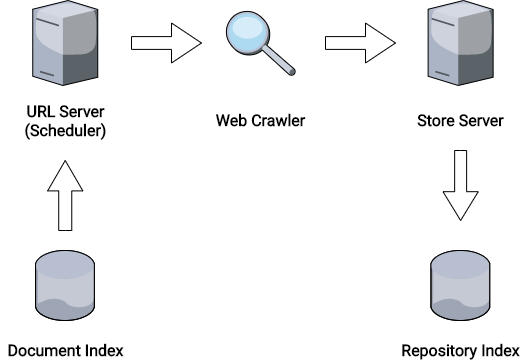
Der URL Server (Scheduler) beliefert den Web Crawler mit URLs, der Store Server speichert die gefundenen Inhalte im Repository Index ab.
Crawler lesen auch die robots.txt einer Seite aus. Hier können Webseitenbetreiber Verzeichnisse ausschließen, die beim Crawling nicht berücksichtigt werden sollen. Da das zeitliche Crawl-Budget eines Crawlers so stark begrenzt ist, lohnt es sich, diese Möglichkeit auch zu nutzen. Damit ist sichergestellt, dass sich der Crawler ausschließlich um notwendige Verzeichnisse kümmert.
Auch die sitemap.xml ist in diesem Zusammenhang zu erwähnen. Besonders bei großen Seiten mit vielen URLs können Crawler diese zur Hilfe nehmen, um zusätzlich auch sehr versteckte (schwach verlinkte) Seiten zu finden.
Indexierung / Information Retrieval
Durch die Webcrawler kennt die Suchmaschine nun zwar eine ganze Menge Websites, doch diese sind im Repository natürlich noch keinem Suchbegriff zugeordnet. Die Aufgabe des Indexers ist es nun entsprechend, diese Zuordnung anhand des Core-Algorithmus vorzunehmen.
Dabei wird zunächst ein Parser aktiv, der die Inhalte des Dokuments in seine Bestandteile zerlegt. Schritt für Schritt werden hier
- HTML- und JavaScript-Tags entfernt
- Logisch zusammenhängende Einheiten identifiziert („Token“)
- Die natürliche Sprache erkannt
- Wörter auf ihren Wortstamm reduziert („Word Stemming“)
- Mehrwortgruppen zerlegt
- Informationslose Wörter herausgefiltert („Stop Words“)
- Keywords extrahiert
Hier lässt sich bereits erkennen, was für die Suchmaschinenoptimierung wirklich relevant ist. Google versucht in diesem Prozess der tatsächlichen semantischen Bedeutung einer Seite nahe zu kommen und filtert die für die Suche unwesentlichen Elemente heraus. Damit wird auch klar, warum Diskussionen darüber, ob eine bestimmte Schreibweise eines Wortes zu mehr Erfolg im Ranking führt, meistens irrelevant sind.
Google wird in diesem Zusammenhang auch nicht müde darin, Webseitenbetreibern zu erklären, dass der entscheidende Rankingfaktor der Content, also die eigentliche Bedeutung der Webseite ist. Darin liegt auch meist das größte Potential.
Nach einem erfolgreichen Parsen des Dokuments hat der Indexer gleich drei weitere Aufgaben:
1. Das Befüllen des Lexikons
Der Wortschatz der Google-Suche ist immens und dennoch wird dieser stets noch erweitert, wenn neue Begriffe gefunden werden. Dafür wird eine weitere Datenbank befüllt, die sämtliche Begriffe enthält, die in den gecrawlten Webseiten enthalten sind. Es mag kaum vorstellbar sein, wieviel Speicher allein durch diese Begriffe belegt sein muss, wenn man bedenkt, wieviele Fachbegriffe in wievielen Sprachen im Internet unterwegs sind.
2. Den Dokumenten-Index erweitern
Damit der URL-Server / Scheduler dem Crawler wieder neue Arbeit liefern kann (siehe Schritt 1 „Web-Crawling“), wird auch der Dokumenten-Index wieder neu mit den in den Webseiten gefundenen Links bestückt. Damit schließt sich der fortwährende Kreislauf aus Crawling und Indexierung.
3. Die Treffer-Liste erstellen
Das Meisterstück im Suchalgorithmus ist schließlich die Zuordnung der im Lexikon enthaltenen Begriffe zu den Webseiten im Dokumentenindex. Hier treibt der gefürchtete Ranking-Algorithmus sein Unwesen. Anhand komplizierter Formeln wird eine permanente Neubewertung dieser Zuordnung vorgenommen und ein Index aufgebaut, der die anschließende Suche erleichtert.
Das geschieht jedoch nicht direkt, sondern über mehrere Ecken. So enthält eine Webseite zunächst mehrere Wort-Terme, die wiederum Begriffen aus dem Lexikon zugeordnet sind.
Somit hat Google an dieser Stelle bereits eine gewisse Rankingreihenfolge für jeden Begriff festgelegt. Die Webseite ist damit indexiert.
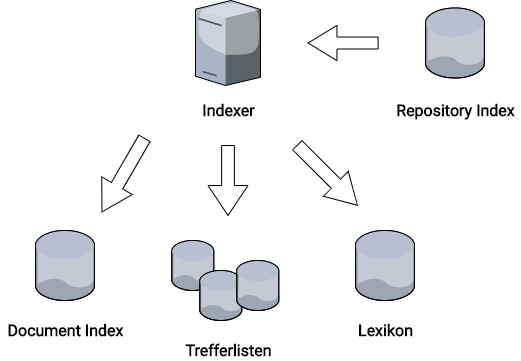
Der Indexer holt sich Inhalte aus dem Repository Index, befüllt das Lexikon mit neuen Suchbegriffen und erstellt Trefferlisten.
Doch auch hier besteht die Möglichkeit, eine Indexierung zu verhindern. So dient die Anweisung
<meta name=“robots“ content=“noindex“ />
dem Google-Bot als Hinweis, diese Seite auszuschließen. Genauso kann mit dem Wert „nofollow“ für das content-Attribut auch verhindert werden, dass weitere Links dieser Seite im Dokumenten-Index landen.
PDFs deindexieren
Doch was ist, wenn es sich um ein PDF und nicht um eine HTML-Seite mit <head> Element handelt? Hier wird ein Zugriff auf die .htaccess benötigt. Mit den folgenden Zeilen kann dem Crawler schon direkt im HTTP-Header mitgeteilt werden, dass das Dokument nicht indexiert werden soll:
<FilesMatch „\.pdf$“> header set x-robots-tag: noindex </FilesMatch>
Query Prozessor
Der Query Prozessor als dritte wesentliche Komponente hat schließlich die Aufgabe, die Suchanfrage des Nutzers zu interpretieren. Suchmaschinen berücksichtigen heute auch wesentlich den Kontext, in dem die Suchanfrage gestellt wurde. Zum Beispiel sollen die demographischen Merkmale, der Standort und vorherige Suchanfragen die Ergebnisse maßgeblich beeinflussen.
Im Query Prozessor müssen also die Terme der eigentlichen Suchanfrage ausgewertet und mit den Begriffen im Lexikon abgeglichen werden. Von dort ergibt sich der Bezug zu den Trefferlisten und unter Berücksichtigung der Nutzerdaten wird entsprechend eine finale, sortierte Liste mit den Dokumenten-IDs erstellt. Der Nutzer erhält also als Ergebnis die organischen Suchergebnisse angezeigt.
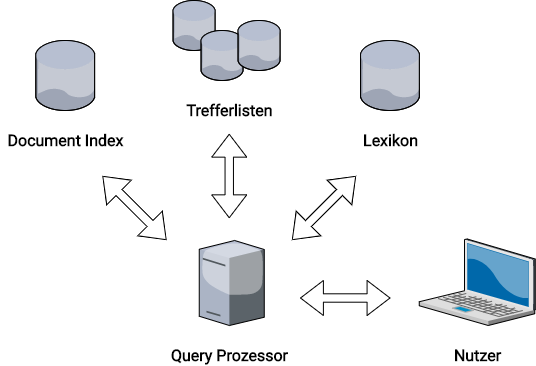
Der Query Prozessor verarbeitet die Nutzereingaben und erstellt eine relevante Suchergebnisliste.
Zusammenfassung
Wie komplex der Aufbau einer Suchmaschine sein kann und wieviele Elemente bei einer Suchanfrage reibungslos zusammenspielen müssen, sollte durch diese vereinfachten Schemata zumindest ansatzweise klar werden. Webseitenbetreiber können dabei vor allem an den Stellschrauben der Indexierung und dem Content drehen.
Letztendlich steckt der Großteil der Suchmaschinenlogik aber in komplexen Algorithmen, auf die Webseitenbetreiber keinen Einfluss haben. Wenn Sie sich in diesem undurchsichtigen Dschungel nicht zurecht finden, ist das nur allzu verständlich. Wir helfen daher gern mit unserem Wissen und unserer Erfahrung, damit Ihr Webauftritt auch inmitten der Konkurrenz für Ihre Zielgruppe sichtbar bleibt.